MarkItDown - GitHub
I just learned about a new open-source tool from Microsoft called MarkItDown.
MarkItDown is a lightweight Python utility for converting various files to Markdown for use with LLMs and related text analysis pipelines.
This seems similar to pandoc, but instead of any being able to take any formatted document type and convert it to any other type, it only outputs to markdown. It can be used as a standalone CLI tool or as a python library.
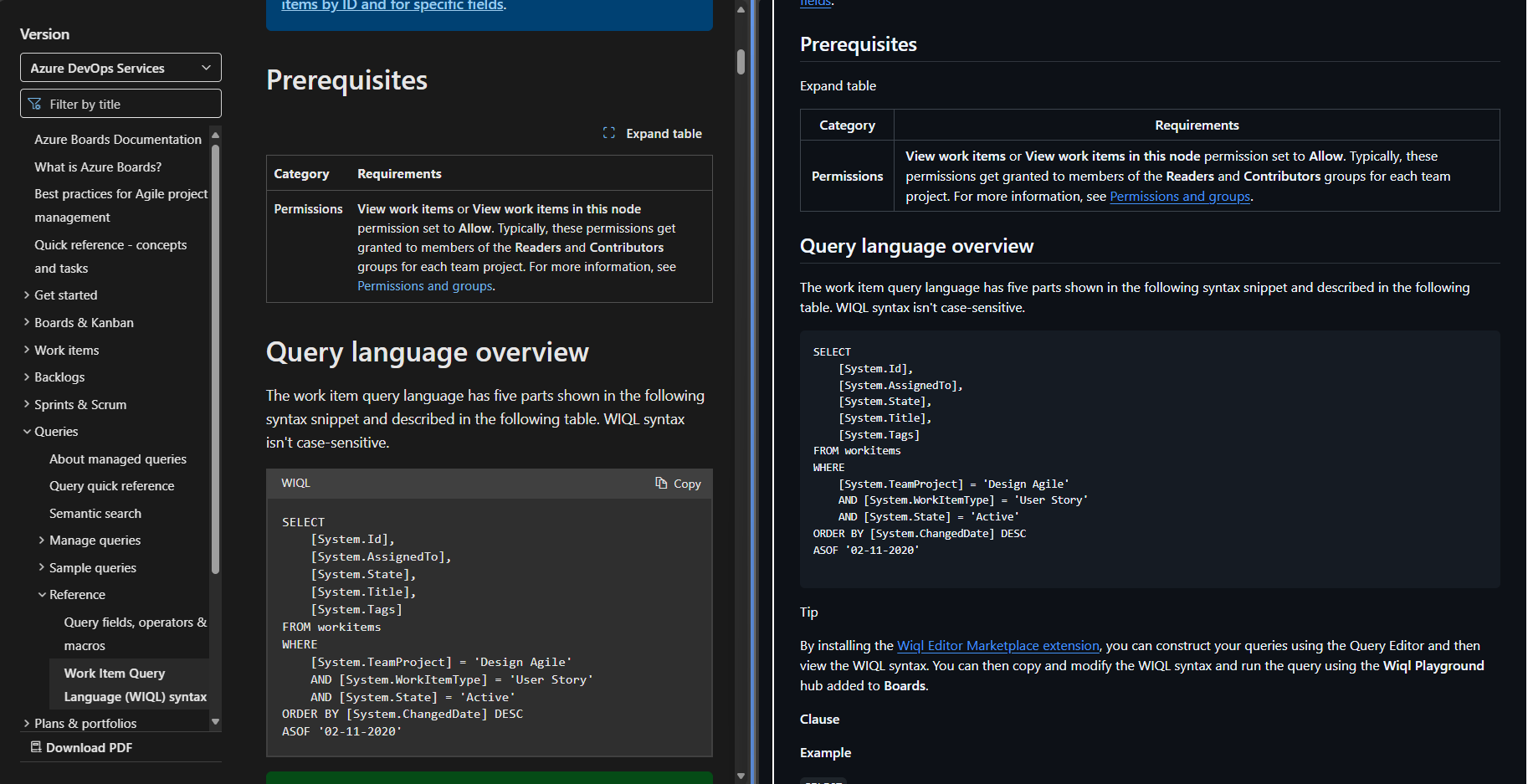
I'm particularly interested in converting HTML to markdown, so that I can take public documentation online and convert it into a markdown file, which can be more effectively consumed by LLMs. I was playing around with this idea last week during a hackathon, where I wanted to take the query language specification for WIQL that is online and turn it into a compact prompt, so the LLM can more reliably create WIQL queries for me.
To get the HTML for the web page, I use Simon Willison's tool shot-scraper to dump the HTML of the webpage, then pipe it into markitdown
shot-scraper html https://learn.microsoft.com/en-us/azure/devops/boards/queries/wiql-syntax | markitdown > wiql.md
This produces a file called wiql.md (link to gist with unmodified output). It's certainly not perfect, the first 300 lines (out of around 1000), are not related to the documentation, and is just extra HTML that isn't needed. This could probably be mitigated by passing an element selector to shot-scraper, so it doesn't dump the unrelated HTML of the page. But it's not hard to delete those lines manually, and then the final result is pretty good. It looks fairly similar to the original web page.
edit: Here is the one-liner to only dump the relevant part of the page.. You have to wrap the output of shot-scraper in a <html> so markitdown can infer the input type.
echo "<html>$(shot-scraper html https://learn.microsoft.com/en-us/azure/devops/boards/queries/wiql-syntax -s .content)</html>" | markitdown -o wiql.md
 MarkItDown also supports plugins, so you can extend it to support other file formats. I've only played around with this a little bit, but I think it will be handy to have a quick and easy way to convert more documents to markdown. I'm particularly interested in the pdf and docx input types as well.
MarkItDown also supports plugins, so you can extend it to support other file formats. I've only played around with this a little bit, but I think it will be handy to have a quick and easy way to convert more documents to markdown. I'm particularly interested in the pdf and docx input types as well.



